Automatic Summarization Library: pysummarization¶
pysummarization is Python3 library for the automatic summarization, document abstraction, and text filtering.
Description¶
The function of this library is automatic summarization using a kind of natural language processing and neural network language model. This library enable you to create a summary with the major points of the original document or web-scraped text that filtered by text clustering. And this library applies accel-brain-base to implement Encoder/Decoder based on LSTM improving the accuracy of summarization by Sequence-to-Sequence(Seq2Seq) learning.
Documentation¶
Full documentation is available on https://code.accel-brain.com/Automatic-Summarization/ . This document contains information on functionally reusability, functional scalability and functional extensibility.
Installation¶
Install using pip:
pip install pysummarization
Source code¶
The source code is currently hosted on GitHub.
Python package index(PyPI)¶
Installers for the latest released version are available at the Python package index.
Dependencies¶
Options¶
- mecab-python3: v0.7 or higher.
- Relevant only for Japanese.
- pdfminer2(or pdfminer.six): latest.
- Relevant only for PDF files.
- pyquery:v1.2.17 or higher.
- Relevant only for web scraiping.
- accel-brain-base: v1.0.0 or higher.
- Only when using Re-Seq2Seq and EncDec-AD.
Usecase: Summarize an English string argument.¶
Import Python modules.
from pysummarization.nlpbase.auto_abstractor import AutoAbstractor
from pysummarization.tokenizabledoc.simple_tokenizer import SimpleTokenizer
from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor
Prepare an English string argument.
document = "Natural language generation (NLG) is the natural language processing task of generating natural language from a machine representation system such as a knowledge base or a logical form. Psycholinguists prefer the term language production when such formal representations are interpreted as models for mental representations."
And instantiate objects and call the method.
# Object of automatic summarization.
auto_abstractor = AutoAbstractor()
# Set tokenizer.
auto_abstractor.tokenizable_doc = SimpleTokenizer()
# Set delimiter for making a list of sentence.
auto_abstractor.delimiter_list = [".", "\n"]
# Object of abstracting and filtering document.
abstractable_doc = TopNRankAbstractor()
# Summarize document.
result_dict = auto_abstractor.summarize(document, abstractable_doc)
# Output result.
for sentence in result_dict["summarize_result"]:
print(sentence)
The result_dict is a dict. this format is as follows.
dict{
"summarize_result": "The list of summarized sentences.",
"scoring_data": "The list of scores(Rank of importance)."
}
Usecase: Summarize Japanese string argument.¶
Import Python modules.
from pysummarization.nlpbase.auto_abstractor import AutoAbstractor
from pysummarization.tokenizabledoc.mecab_tokenizer import MeCabTokenizer
from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor
Prepare an English string argument.
document = "自然言語処理(しぜんげんごしょり、英語: natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。「計算言語学」(computational linguistics)との類似もあるが、自然言語処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす事が多い[1]。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。"
And instantiate objects and call the method.
# Object of automatic summarization.
auto_abstractor = AutoAbstractor()
# Set tokenizer for Japanese.
auto_abstractor.tokenizable_doc = MeCabTokenizer()
# Set delimiter for making a list of sentence.
auto_abstractor.delimiter_list = ["。", "\n"]
# Object of abstracting and filtering document.
abstractable_doc = TopNRankAbstractor()
# Summarize document.
result_dict = auto_abstractor.summarize(document, abstractable_doc)
# Output result.
for sentence in result_dict["summarize_result"]:
print(sentence)
Usecase: English Web-Page Summarization¶
Run the batch program: demo/demo_summarization_english_web_page.py
python demo/demo_summarization_english_web_page.py {URL}
- {URL}: web site URL.
Demo¶
Let’s summarize this page: Natural_language_generation - Wikipedia.
python demo/demo_summarization_english_web_page.py https://en.wikipedia.org/wiki/Natural_language_generation
The result is as follows.
Natural language generation From Wikipedia, the free encyclopedia Jump to: navigation , search Natural language generation ( NLG ) is the natural language processing task of generating natural language from a machine representation system such as a knowledge base or a logical form .
Psycholinguists prefer the term language production when such formal representations are interpreted as models for mental representations.
It could be said an NLG system is like a translator that converts data into a natural language representation.
Usecase: Japanese Web-Page Summarization¶
Run the batch program: demo/demo_summarization_japanese_web_page.py
python demo/demo_summarization_japanese_web_page.py {URL}
- {URL}: web site URL.
Demo¶
Let’s summarize this page: 自動要約 - Wikipedia.
python demo/demo_summarization_japanese_web_page.py https://ja.wikipedia.org/wiki/%E8%87%AA%E5%8B%95%E8%A6%81%E7%B4%84
The result is as follows.
自動要約 (じどうようやく)は、 コンピュータプログラム を用いて、文書からその要約を作成する処理である。
自動要約の応用先の1つは Google などの 検索エンジン であるが、もちろん独立した1つの要約プログラムといったものもありうる。
単一文書要約と複数文書要約 [ 編集 ] 単一文書要約 は、単一の文書を要約の対象とするものである。
例えば、1つの新聞記事を要約する作業は単一文書要約である。
Usecase: Japanese Web-Page Summarization with N-gram¶
The minimum unit of token is not necessarily a word in automatic summarization. N-gram is also applicable to the tokenization.
Run the batch program: demo/demo_with_n_gram_japanese_web_page.py
python demo_with_n_gram_japanese_web_page.py {URL}
- {URL}: web site URL.
Demo¶
Let’s summarize this page:情報検索 - Wikipedia.
python demo/demo_with_n_gram_japanese_web_page.py https://ja.wikipedia.org/wiki/%E6%83%85%E5%A0%B1%E6%A4%9C%E7%B4%A2
The result is as follows.
情報検索アルゴリズムの詳細については 情報検索アルゴリズム を参照のこと。
パターンマッチング 検索質問として入力された表現をそのまま含む文書を検索するアルゴリズム。
ベクトル空間モデル キーワード等を各 次元 として設定した高次元 ベクトル空間 を想定し、検索の対象とするデータやユーザによる検索質問に何らかの加工を行い ベクトル を生成する
Usecase: Summarization, filtering the mutually similar, tautological, pleonastic, or redundant sentences¶
If the sentences you want to summarize consist of repetition of same or similar sense in different words, the summary results may also be redundant. Then before summarization, you should filter the mutually similar, tautological, pleonastic, or redundant sentences to extract features having an information quantity. The function of SimilarityFilter is to cut-off the sentences having the state of resembling or being alike by calculating the similarity measure.
But there is no reason to stick to a single similarity concept. Modal logically, the definition of this concept is contingent, like the concept of distance. Even if one similarity or distance function is defined in relation to a problem setting, there are always functionally equivalent algorithms to solve the problem setting. Then this library has a wide variety of subtyping polymorphisms of SimilarityFilter.
Dice, Jaccard, and Simpson¶
There are some classes for calculating the similarity measure. In this library, Dice coefficient, Jaccard coefficient, and Simpson coefficient between two sentences is calculated as follows.
Import Python modules for calculating the similarity measure and instantiate the object.
from pysummarization.similarityfilter.dice import Dice
similarity_filter = Dice()
or
from pysummarization.similarityfilter.jaccard import Jaccard
similarity_filter = Jaccard()
or
from pysummarization.similarityfilter.simpson import Simpson
similarity_filter = Simpson()
Functional equivalent: Combination of Tf-Idf and Cosine similarity¶
If you want to calculate similarity with Tf-Idf cosine similarity, instantiate TfIdfCosine.
from pysummarization.similarityfilter.tfidf_cosine import TfIdfCosine
similarity_filter = TfIdfCosine()
Calculating similarity¶
If you want to calculate similarity between two sentences, call calculate method as follow.
# Tokenized sentences
token_list_x = ["Dice", "coefficient", "is", "a", "similarity", "measure", "."]
token_list_y = ["Jaccard", "coefficient", "is", "a", "similarity", "measure", "."]
# 0.75
similarity_num = similarity_filter.calculate(token_list_x, token_list_y)
Filtering similar sentences and summarization¶
The function of these methods is to cut-off mutually similar sentences. In text summarization, basic usage of this function is as follow. After all, SimilarityFilter is delegated as well as GoF’s Strategy Pattern.
Import Python modules for NLP and text summarization.
from pysummarization.nlp_base import NlpBase
from pysummarization.nlpbase.auto_abstractor import AutoAbstractor
from pysummarization.tokenizabledoc.mecab_tokenizer import MeCabTokenizer
from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor
from pysummarization.similarityfilter.tfidf_cosine import TfIdfCosine
Instantiate object of the NLP.
# The object of the NLP.
nlp_base = NlpBase()
# Set tokenizer. This is japanese tokenizer with MeCab.
nlp_base.tokenizable_doc = MeCabTokenizer()
Instantiate object of SimilarityFilter and set the cut-off threshold.
# The object of `Similarity Filter`.
# The similarity observed by this object is so-called cosine similarity of Tf-Idf vectors.
similarity_filter = TfIdfCosine()
# Set the object of NLP.
similarity_filter.nlp_base = nlp_base
# If the similarity exceeds this value, the sentence will be cut off.
similarity_filter.similarity_limit = 0.25
Prepare sentences you want to summarize.
# Summarized sentences (sited from http://ja.uncyclopedia.info/wiki/%E5%86%97%E8%AA%9E%E6%B3%95).
document = "冗語法(じょうごほう、レデュンダンシー、redundancy、jōgohō)とは、何度も何度も繰り返し重ねて重複して前述されたのと同じ意味の同様である同意義の文章を、必要あるいは説明か理解を要求された以上か、伝え伝達したいと意図された、あるいは表し表現したい意味以上に、繰り返し重ねて重複して繰り返すことによる、不必要であるか、または余分な余計である文章の、必要以上の使用であり、何度も何度も繰り返し重ねて重複して前述されたのと同じ意味の同様の文章を、必要あるいは説明か理解を要求された以上か、伝え伝達したいと意図された、あるいは表し表現したい意味以上に、繰り返し重ねて重複して繰り返すことによる、不必要であるか、または余分な文章の、必要以上の使用である。これが冗語法(じょうごほう、レデュンダンシー、redundancy、jōgohō)である。基本的に、冗語法(じょうごほう、レデュンダンシー、redundancy、jōgohō)が多くの場合において概して一般的に繰り返される通常の場合は、普通、同じ同様の発想や思考や概念や物事を表し表現する別々の異なった文章や単語や言葉が何回も何度も余分に繰り返され、その結果として発言者の考えが何回も何度も言い直され、事実上、実際に同じ同様の発言が何回も何度にもわたり、幾重にも言い換えられ、かつ、同じことが何回も何度も繰り返し重複して過剰に回数を重ね前述されたのと同じ意味の同様の文章が何度も何度も不必要に繰り返される。通常の場合、多くの場合において概して一般的にこのように冗語法(じょうごほう、レデュンダンシー、redundancy、jōgohō)が繰り返される。"
Instantiate object of AutoAbstractor and call the method.
# The object of automatic sumamrization.
auto_abstractor = AutoAbstractor()
# Set tokenizer. This is japanese tokenizer with MeCab.
auto_abstractor.tokenizable_doc = MeCabTokenizer()
# Object of abstracting and filtering document.
abstractable_doc = TopNRankAbstractor()
# Delegate the objects and execute summarization.
result_dict = auto_abstractor.summarize(document, abstractable_doc, similarity_filter)
Demo¶
Let’s summarize this page:循環論法 - Wikipedia.
Run the batch program: demo/demo_similarity_filtering_japanese_web_page.py
python demo/demo_similarity_filtering_japanese_web_page.py {URL} {SimilarityFilter} {SimilarityLimit}
- {URL}: web site URL.
- {SimilarityFilter}: The object of
SimilarityFilter:DiceJaccardSimpsonTfIdfCosine
- {SimilarityLimit}: The cut-off threshold.
For instance, command line argument is as follows:
python demo/demo_similarity_filtering_japanese_web_page.py https://ja.wikipedia.org/wiki/%E5%BE%AA%E7%92%B0%E8%AB%96%E6%B3%95 Jaccard 0.3
The result is as follows.
循環論法 出典: フリー百科事典『ウィキペディア(Wikipedia)』 移動先: 案内 、 検索 循環論法 (じゅんかんろんぽう、circular reasoning, circular logic, vicious circle [1] )とは、 ある命題の 証明 において、その命題を仮定した議論を用いること [1] 。
証明すべき結論を前提として用いる論法 [2] 。
ある用語の 定義 を与える表現の中にその用語自体が本質的に登場していること [1]
Usecase: Summarization with Neural Network Language Model.¶
According to the neural networks theory, and in relation to manifold hypothesis, it is well known that multilayer neural networks can learn features of observed data points and have the feature points in hidden layer. High-dimensional data can be converted to low-dimensional codes by training the model such as Stacked Auto-Encoder and Encoder/Decoder with a small central layer to reconstruct high-dimensional input vectors. This function of dimensionality reduction facilitates feature expressions to calculate similarity of each data point.
This library provides Encoder/Decoder based on LSTM, which makes it possible to extract series features of natural sentences embedded in deeper layers by sequence-to-sequence learning. Intuitively speaking, similarities of the series feature points correspond to similarities of the observed data points. If we believe this hypothesis, the following models become in principle possible.
retrospective sequence-to-sequence learning(re-seq2seq).¶
The concept of the re-seq2seq(Zhang, K. et al., 2018) provided inspiration to this library. This model is a new sequence learning model mainly in the field of Video Summarizations. “The key idea behind re-seq2seq is to measure how well the machine-generated summary is similar to the original video in an abstract semantic space” (Zhang, K. et al., 2018, p3).
The encoder of a seq2seq model observes the original video and output feature points which represents the semantic meaning of the observed data points. Then the feature points is observed by the decoder of this model. Additionally, in the re-seq2seq model, the outputs of the decoder is propagated to a retrospective encoder, which infers feature points to represent the semantic meaning of the summary. “If the summary preserves the important and relevant information in the original video, then we should expect that the two embeddings are similar (e.g. in Euclidean distance)” (Zhang, K. et al., 2018, p3).
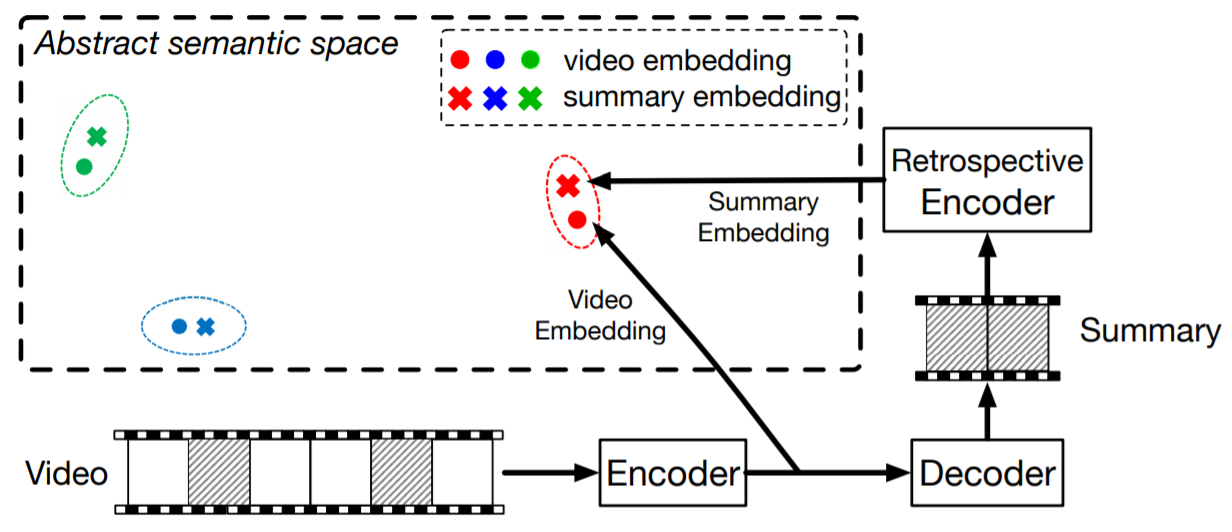
Zhang, K., Grauman, K., & Sha, F. (2018). Retrospective Encoders for Video Summarization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 383-399), p2.
This library refers to this intuitive insight above to apply the model to text summarizations. Like videos, semantic feature representation based on representation learning of manifolds is also possible in text summarizations.
The intuition in the design of their loss function is also suggestive. “The intuition behind our modeling is that the outputs should convey the same amount of information as the inputs. For summarization, this is precisely the goal: a good summary should be such that after viewing the summary, users would get about the same amount of information as if they had viewed the original video” (Zhang, K. et al., 2018, p7).
Building retrospective sequence-to-sequence learning(re-seq2seq).¶
Import Python modules.
from pysummarization.abstractablesemantics._mxnet.re_seq_2_seq import ReSeq2Seq
from pysummarization.iteratabledata._mxnet.token_iterator import TokenIterator
from pysummarization.nlp_base import NlpBase
from pysummarization.tokenizabledoc.simple_tokenizer import SimpleTokenizer
from pysummarization.vectorizabletoken.t_hot_vectorizer import THotVectorizer
import mxnet as mx
Setup a logger.
from logging import getLogger, StreamHandler, NullHandler, DEBUG, ERROR
logger = getLogger("accelbrainbase")
handler = StreamHandler()
handler.setLevel(DEBUG)
logger.setLevel(DEBUG)
logger.addHandler(handler)
Initialize a tokenizer and a vectorizer.
# `str` of your document.
document = "Your document."
nlp_base = NlpBase()
nlp_base.delimiter_list = [".", "\n"]
tokenizable_doc = SimpleTokenizer()
sentence_list = nlp_base.listup_sentence(document)
token_list = tokenizable_doc.tokenize(document)
Setup the vectorizer.
vectorizable_token = THotVectorizer(token_list=token_arr.tolist())
vector_list = vectorizable_token.vectorize(token_list=token_arr.tolist())
vector_arr = np.array(vector_list)
token_arr = np.array(token_list)
token_iterator = TokenIterator(
vectorizable_token=vectorizable_token,
token_arr=token_arr,
epochs=300,
batch_size=25,
seq_len=5,
test_size=0.3,
norm_mode=None,
ctx=mx.gpu()
)
for observed_arr, _, _, _ in token_iterator.generate_learned_samples():
break
print(observed_arr.shape) # (batch size, the length of series, dimension)
Instantiate ReSeq2Seq and input hyperparameters.
abstractable_semantics = ReSeq2Seq(
# The default parameter. The number of units in hidden layers.
hidden_neuron_count=observed_arr.shape[-1],
# The default parameter. The number of units in output layer.
output_neuron_count=observed_arr.shape[-1],
# The rate of dropout.
dropout_rate=0.0,
# Batch size.
batch_size=25,
# Learning rate.
learning_rate=1e-05,
# The length of series.
seq_len=5,
# `mx.gpu()` or `mx.cpu()`.
ctx=mx.gpu()
)
Execute learn method.
abstractable_semantics.learn(
# is-a `TokenIterator`.
token_iterator
)
Execute summarize method to extract summaries.
abstract_list = abstractable_semantics.summarize(
# is-a `TokenIterator`.
token_iterator,
# is-a `VectorizableToken`.
vectorizable_token,
# `list` of `str`, extracted by `nlp_base.listup_sentence(document)`.
sentence_list,
# The number of extracted sentences.
limit=5
)
The abstract_list is a list that contains strs of sentences.
Functional equivalent: LSTM-based Encoder/Decoder scheme for Anomaly Detection (EncDec-AD).¶
This library applies the Encoder-Decoder scheme for Anomaly Detection (EncDec-AD) to text summarizations by intuition. In this scheme, LSTM-based Encoder/Decoder or so-called the sequence-to-sequence(Seq2Seq) model learns to reconstruct normal time-series behavior, and thereafter uses reconstruction error to detect anomalies.
Malhotra, P., et al. (2016) showed that EncDecAD paradigm is robust and can detect anomalies from predictable, unpredictable, periodic, aperiodic, and quasi-periodic time-series. Further, they showed that the paradigm is able to detect anomalies from short time-series (length as small as 30) as well as long time-series (length as large as 500).
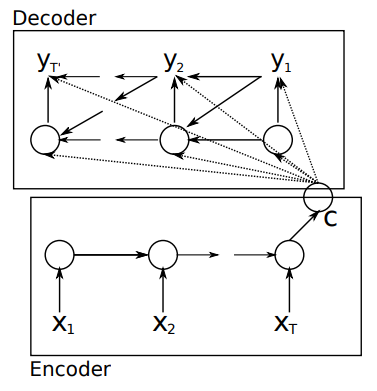
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078., p2.
This library refers to the intuitive insight in relation to the use case of reconstruction error to detect anomalies above to apply the model to text summarization. As exemplified by Seq2Seq paradigm, document and sentence which contain tokens of text can be considered as time-series features. The anomalies data detected by EncDec-AD should have to express something about the text.
From the above analogy, this library introduces two conflicting intuitions. On the one hand, the anomalies data may catch observer’s eye from the viewpoints of rarity or amount of information as the indicator of natural language processing like TF-IDF shows. On the other hand, the anomalies data may be ignorable noise as mere outlier.
In any case, this library deduces the function and potential of EncDec-AD in text summarization is to draw the distinction of normal and anomaly texts and is to filter the one from the other.
Building LSTM-based Encoder/Decoder scheme for Anomaly Detection (EncDec-AD).¶
Import Python modules.
from pysummarization.abstractablesemantics._mxnet.enc_dec_ad import EncDecAD
from pysummarization.iteratabledata._mxnet.token_iterator import TokenIterator
from pysummarization.nlp_base import NlpBase
from pysummarization.tokenizabledoc.simple_tokenizer import SimpleTokenizer
import mxnet as mx
Setup a logger.
from logging import getLogger, StreamHandler, NullHandler, DEBUG, ERROR
logger = getLogger("accelbrainbase")
handler = StreamHandler()
handler.setLevel(DEBUG)
logger.setLevel(DEBUG)
logger.addHandler(handler)
Initialize a tokenizer and a vectorizer.
# `str` of your document.
document = "Your document."
nlp_base = NlpBase()
nlp_base.delimiter_list = [".", "\n"]
tokenizable_doc = SimpleTokenizer()
sentence_list = nlp_base.listup_sentence(document)
token_list = tokenizable_doc.tokenize(document)
Setup the vectorizer.
vectorizable_token = THotVectorizer(token_list=token_arr.tolist())
vector_list = vectorizable_token.vectorize(token_list=token_arr.tolist())
vector_arr = np.array(vector_list)
token_arr = np.array(token_list)
token_iterator = TokenIterator(
vectorizable_token=vectorizable_token,
token_arr=token_arr,
epochs=300,
batch_size=25,
seq_len=5,
test_size=0.3,
norm_mode=None,
ctx=mx.gpu()
)
for observed_arr, _, _, _ in token_iterator.generate_learned_samples():
break
print(observed_arr.shape) # (batch size, the length of series, dimension)
Instantiate EncDecAD and input hyperparameters.
abstractable_semantics = EncDecAD(
# The default parameter. The number of units in hidden layers.
hidden_neuron_count=200,
# The default parameter. The number of units in output layer.
output_neuron_count=observed_arr.shape[-1],
# The rate of dropout.
dropout_rate=0.0,
# Batch size.
batch_size=25,
# Learning rate.
learning_rate=1e-05,
# The length of series.
seq_len=5,
# `mx.gpu()` or `mx.cpu()`.
ctx=mx.gpu()
)
Execute learn method.
abstractable_semantics.learn(
# is-a `TokenIterator`.
token_iterator
)
Execute summarize method to extract summaries.
abstract_list = abstractable_semantics.summarize(
# is-a `TokenIterator`.
token_iterator,
# is-a `VectorizableToken`.
vectorizable_token,
# `list` of `str`, extracted by `nlp_base.listup_sentence(document)`.
sentence_list,
# The number of extracted sentences.
limit=5
)
The abstract_list is a list that contains strs of sentences.
References¶
- Boulanger-Lewandowski, N., Bengio, Y., & Vincent, P. (2012). Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and transcription. arXiv preprint arXiv:1206.6392.
- Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
- Luhn, Hans Peter. “The automatic creation of literature abstracts.” IBM Journal of research and development 2.2 (1958): 159-165.
- Malhotra, P., Ramakrishnan, A., Anand, G., Vig, L., Agarwal, P., & Shroff, G. (2016). LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv preprint arXiv:1607.00148.
- Matthew A. Russell 著、佐藤 敏紀、瀬戸口 光宏、原川 浩一 監訳、長尾 高弘 訳『入門 ソーシャルデータ 第2版――ソーシャルウェブのデータマイニング』 2014年06月 発行
- Sutskever, I., Hinton, G. E., & Taylor, G. W. (2009). The recurrent temporal restricted boltzmann machine. In Advances in Neural Information Processing Systems (pp. 1601-1608).
- Zhang, K., Grauman, K., & Sha, F. (2018). Retrospective Encoders for Video Summarization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 383-399).
More detail demos¶
- Webクローラ型人工知能:キメラ・ネットワークの仕様 (Japanese)
- 20001 bots are running as 20001 web-crawlers and 20001 web-scrapers.
- 「代理演算」一覧 | Welcome to Singularity (Japanese)
- 20001 bots are running as 20001 blogers and 20001 “content curation writers”.
Author¶
- accel-brain
Author URI¶
- https://accel-brain.co.jp/
- https://accel-brain.com/
License¶
- GNU General Public License v2.0