Algorithmic Composition or Automatic Composition Library: pycomposer¶
pycomposer is Python library for Algorithmic Composition or Automatic Composition based on the stochastic music theory and the Statistical machine learning problems. Especialy, this library provides apprication of the Algorithmic Composer based on Conditional Generative Adversarial Networks(Conditional GANs).
Installation¶
Install using pip:
pip install pycomposer
Source code¶
The source code is currently hosted on GitHub.
Python package index(PyPI)¶
Installers for the latest released version are available at the Python package index.
Dependencies¶
- numpy: v1.13.3 or higher.
- pandas: v0.22.0 or higher.
- pretty_midi: latest.
- accel-brain-base: v1.0.0 or higher.
Documentation¶
Full documentation is available on https://code.accel-brain.com/Algorithmic-Composition/ . This document contains information on functionally reusability, functional scalability and functional extensibility.
Description¶
pycomposer is Python library which provides wrapper classes for:
- reading sequencial data from MIDI files,
- extracting feature points of observed data points from this sequencial data by generative models,
- generating new sequencial data by compositions based on Generative models,
- and converting the data into new MIDI file.
Generative Adversarial Networks(GANs)¶
In order to realize these functions, this library implements algorithms of Algorithmic Composer based on Generative Adversarial Networks(GANs) (Goodfellow et al., 2014) framework which establishes a min-max adversarial game between two neural networks – a generative model, G, and a discriminative model, D. The discriminator model, D(x), is a neural network that computes the probability that a observed data point x in data space is a sample from the data distribution (positive samples) that we are trying to model, rather than a sample from our generative model (negative samples). Concurrently, the generator uses a function G(z) that maps samples z from the prior p(z) to the data space. G(z) is trained to maximally confuse the discriminator into believing that samples it generates come from the data distribution. The generator is trained by leveraging the gradient of D(x) w.r.t. x, and using that to modify its parameters.
Architecture design¶
This library is designed following the above theory. The composer GANComposer learns observed data points drawn from a true distribution of input MIDI files and generates feature points drawn from a fake distribution that means such as Uniform distribution or Normal distribution, imitating the true MIDI files data.
The components included in this composer are functionally differentiated into three models.
TrueSampler.Generator.Discriminator.
The function of TrueSampler is to draw samples from a true distribution of input MIDI files. Generator has NoiseSamplers and draw fake samples from a Uniform distribution or Normal distribution by use it. And Discriminator observes those input samples, trying discriminating true and fake data.
By default, Generator and Discriminator are built as LSTM networks, observing MIDI data separated by fixed sequence length and time resolution. While Discriminator observes Generator’s observation to discrimine the output from true samples, Generator observes Discriminator’s observations to confuse Discriminators judgments. In GANs framework, the mini-max game can be configured by the observations of observations.
After this game, the Generator will grow into a functional equivalent that enables to imitate the TrueSampler and makes it possible to compose similar but slightly different music by the imitation.
Data Representation¶
Following MidiNet and MuseGAN(Dong, H. W., et al., 2018), this class consider bars as the basic compositional unit for the fact that harmonic changes usually occur at the boundaries of bars and that human beings often use bars as the building blocks when composing songs. The feature engineering in this class also is inspired by the Multi-track piano-roll representations in MuseGAN.
But their strategies of activation function did not apply to this library since its methods can cause information losses. The models just binarize the Generator’s output, which uses tanh as an activation function in the output layer, by a threshold at zero, or by deterministic or stochastic binary neurons(Bengio, Y., et al., 2018, Chung, J., et al., 2016), and ignore drawing a distinction the consonance and the dissonance.
This library simply uses the softmax strategy. This class stochastically selects a combination of pitches in each bars drawn by the true MIDI files data, based on the difference between consonance and dissonance intended by the composer of the MIDI files.
Usecase: Composed of multi instruments/tracks by Conditional GANs.¶
Here, referring to the case of MidiNet model for symbolic-domain music generation(Yang, L. C., et al., 2017), Conditional GAN is used as an algorithm for composing music. MidiNet can be expanded to generate music with multiple MIDI channels (i.e. tracks), using convolutional and deconvolutional neural networks. MidiNet can be expanded to generate music with multiple MIDI channels (i.e. tracks), using convolutional and deconvolutional neural networks.
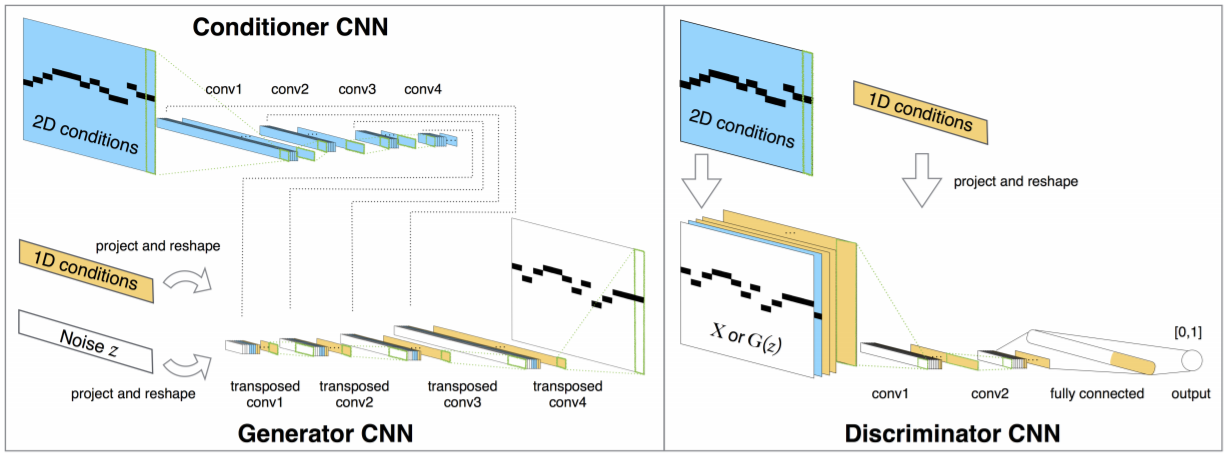
Yang, L. C., Chou, S. Y., & Yang, Y. H. (2017). MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. arXiv preprint arXiv:1703.10847., p3.
Import and setup modules.¶
Make settings for this library and for visualization.
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
%config InlineBackend.figure_format = "retina"
plt.style.use("fivethirtyeight")
Import Python modules.
from pycomposer.gancomposable.conditional_gan_composer import ConditionalGANComposer
Let’s make it possible to confirm later that learning is working according to GAN theory by the logger of Python.
from logging import getLogger, StreamHandler, NullHandler, DEBUG, ERROR
logger = getLogger("pygan")
handler = StreamHandler()
handler.setLevel(DEBUG)
logger.setLevel(DEBUG)
logger.addHandler(handler)
Instantiate the required class.
gan_composer = ConditionalGANComposer(
# `list` of Midi files to learn.
midi_path_list=[
"../../../../Downloads/Beethoven_gekko_3_k.mid"
],
# Batch size.
batch_size=20,
# The length of sequence that LSTM networks will observe.
seq_len=8,
# Learning rate in `Generator` and `Discriminator`.
learning_rate=1e-10,
# Time fraction or time resolution (seconds).
time_fraction=0.5,
)
Learning.¶
The learning algorithm is based on a mini-batch stochastic gradient descent training of generative adversarial nets. The number of steps to apply to the discriminator, k_step, is a hyperparameter. For instance, Goodfellow, I. et al.(2014) used k = 1, the least expensive option. Not limited to this parameter, the appropriate value of the hyperparameter is unknown.
gan_composer.learn(
# The number of training iterations.
iter_n=1000,
# The number of learning of the `discriminator`.
k_step=10
)
Inferencing.¶
After learning, gan_composer enables to compose melody and new MIDI file by learned model. In relation to MIDI data, pitch is generated from a learned generation model. start and end are generated by calculating back from length of sequences and time resolution. On the other hand, velocity is sampled from Gaussian distribution.
gan_composer.compose(
# Path to generated MIDI file.
file_path="path/to/new/midi/file.mid",
# Mean of velocity.
# This class samples the velocity from a Gaussian distribution of
# `velocity_mean` and `velocity_std`.
# If `None`, the average velocity in MIDI files set to this parameter.
velocity_mean=None,
# Standard deviation(SD) of velocity.
# This class samples the velocity from a Gaussian distribution of
# `velocity_mean` and `velocity_std`.
# If `None`, the SD of velocity in MIDI files set to this parameter.
velocity_std=None
)
Finally, new MIDI file will be stored in file_path.
If you want to know more detailed implementation and log visualization, see my notebook.
References¶
- Bengio, Y., Léonard, N., & Courville, A. (2013). Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432.
- Chung, J., Ahn, S., & Bengio, Y. (2016). Hierarchical multiscale recurrent neural networks. arXiv preprint arXiv:1609.01704.
- Dong, H. W., Hsiao, W. Y., Yang, L. C., & Yang, Y. H. (2018, April). MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Fang, W., Zhang, F., Sheng, V. S., & Ding, Y. (2018). A method for improving CNN-based image recognition using DCGAN. Comput. Mater. Contin, 57, 167-178.
- Gauthier, J. (2014). Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester, 2014(5), 2.
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
- Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431-3440).
- Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I., & Frey, B. (2015). Adversarial autoencoders. arXiv preprint arXiv:1511.05644.
- Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
- Yang, L. C., Chou, S. Y., & Yang, Y. H. (2017). MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. arXiv preprint arXiv:1703.10847.
Author¶
- accel-brain
Author URI¶
- https://accel-brain.co.jp/
- https://accel-brain.com/
License¶
- GNU General Public License v2.0